DomainCrawler
В целом бота DomainCrawler можно назвать "вежливым", но "напористым". Далее рассмотрим его поведение, откуда он и что хочет, что пишется в логи и дополнительную информацию об этом боте.
Информации о боте
Как и все "порядочные" боты он указывает контактные данные для подробной информации о нем и обратной связи. В Useragent передает два вида контактов:
- Email: info@domaincrawler.com
- Сайт: http://www.domaincrawler.com/
На официальном сайте бота, на странице "About Us" указывается его миссия. Как я понял главной миссией этого бота - сбор информации о сайтах и SEO данных в национальных доменных зонах (ccTLDs). В целом сайт походит на онлайн-сервис для анализа основных параметров сайта, где введя адрес желаемого сайта вам покажут известную информацию о нем.
DomainCrawler в логах
В логах указано значение "%DOMAIN%" - это доменное имя сайта, который он сканирует, т.е. вашего сайта, раз вы увидели это в логах.
80.248.225.79 [10/Mar/2019:14:26:24 +0300] "GET / HTTP/1.1" 200 274633 0.453 "-" "DomainCrawler/3.0 (info@domaincrawler.com; http://www.domaincrawler.com/%DOMAIN%)"Кроме него по похожим контактным данным приходит и бот "CipaCrawler", который запрашивает файлы: /robots.txt, /ads.txt, /humans.txt и главную страницу. Бот CipaCrawler уже не входит в рамки описания этого материала и при необходимости будет рассмотрен отдельно.
Поведение бота
Перед началом сканирования этот бот запрашивает файл /robots.txt, следует полагать, что он может слушаться указаний вебмастера - это хорошо. Поведение бота вызывает подозрения со стороны частоты запросов в секунду - по 1 запросу в секунду на протяжении 2-4 часов. Например за 10 марта 2019 года этот бот произвел 9821 запросов к сайту. Этот бот действует как типичный "паук" - запрашивает главную страницу, берет ссылки, обходит эти ссылки, берет с них ссылки и т.д.
Частота сканирования непредсказуема, этот бот может прийти в любой момент. За все случаи его появления бот производил обращения с двух IP: 185.6.8.9 и 80.248.225.79. Оба IP адреса находятся в Швеции и по мнению других вебмастеров, в базе AbuseIPDB, есть жалобы на запросы с этих IP адресов, где есть упоминания и о том, что игнорируются директивы в "/robots.txt" (хотя администрация AbuseIPDB и внесла эти IP в "белый список").
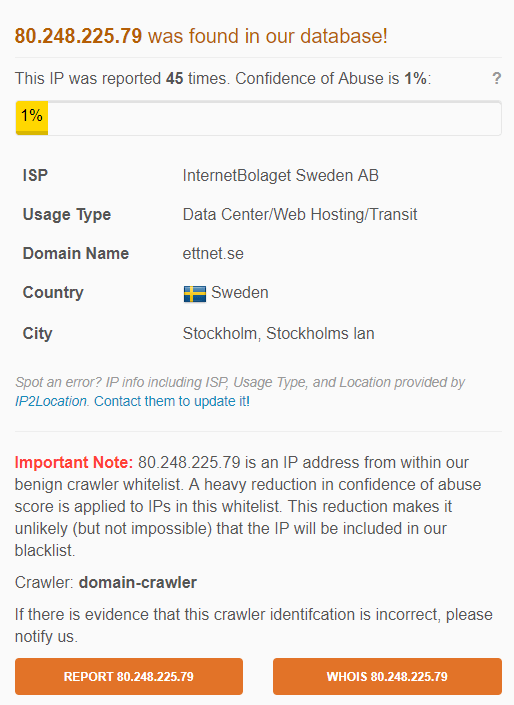
Сводная информация о боте
Исходя из вышеописанного можно понять следующее:
- перед сканированием смотрит
/robots.txt(не проверял слушает или нет указания вебмастера); - указывает контактные данные;
- может выполнять по 1 запросу в секунду;
- использует типичную тактику "паука" при обходе сайта;
- под такими же контактными данными заходил и под именем "CipaCrawler";
- бот делает запросы из Швеции;
- пользу для вашего сайта не несет и может быть заблокирован, без ущерба для вашего SEO.
Есть что дополнить или нашли что можно исправить? Напишите, пожалуйста, об этом в "Есть что добавить" (слева синяя кнопка)